etickr.com – Manusia memahami dunia melalui lima indera—melihat gambar, mendengar suara, membaca teks, merasakan sentuhan. Multimodal Machine Learning (MML) adalah paradigma AI baru yang meniru kemampuan ini: mengintegrasikan data dari berbagai modalitas (teks, gambar, audio, video, sensor) untuk pemahaman yang lebih kaya dan akurat. Dari GPT-4o hingga Gemini 1.5, MML telah melampaui unimodal AI—meningkatkan akurasi 30–50% di tugas kompleks (ICML 2025).
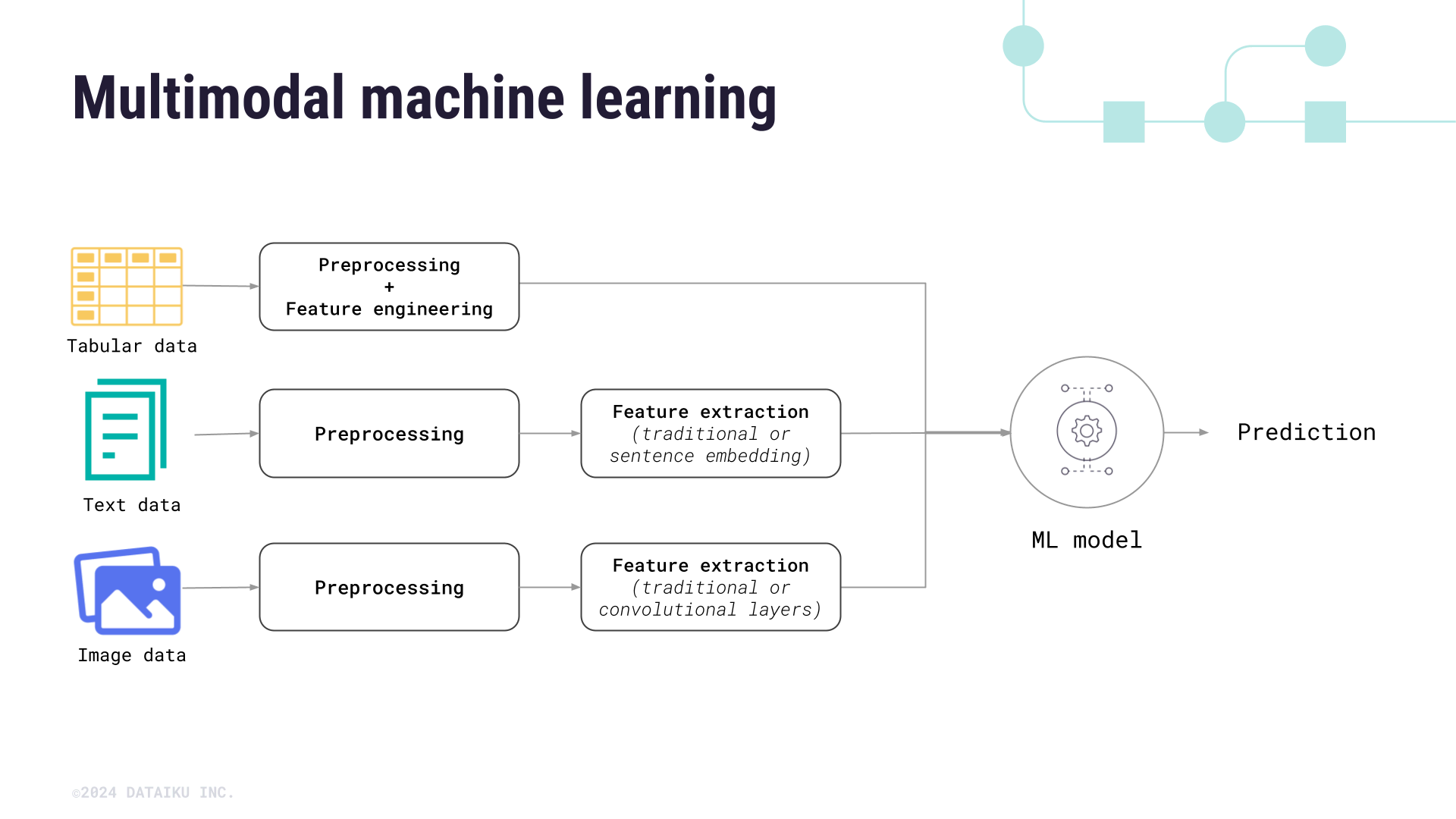
1. Definisi: Lebih dari Sekadar “Text + Image”
MML = model AI yang memproses ≥2 jenis data input secara bersamaan untuk menghasilkan output yang lebih kontekstual. Contoh:
- Input: Gambar + teks caption
- Output: Jawaban pertanyaan visual (VQA)
- Keunggulan: Cross-modal reasoning, robustness terhadap noise, generalization
2. Sejarah Singkat MML
| Tahun |
Milestone |
Kontribusi |
| 2017 |
Visual Question Answering (VQA) |
Dataset VQA 1.0 – awal integrasi vision+language |
| 2019 |
ViLBERT, LXMERT |
Dual-stream transformer: pisah proses gambar & teks |
| 2021 |
CLIP (OpenAI) |
Contrastive learning: align image-text embedding |
| 2022 |
Flamingo, BLIP-2 |
Single-stream: fusion dini dengan cross-attention |
| 2023 |
GPT-4V, LLaVA |
Multimodal LLM: teks + gambar + audio |
| 2024 |
Gemini 1.5, Chameleon |
Native multimodal: proses 1M token (video+audio+teks) |
| 2025 |
Grok-3 Vision, Qwen-VL-2 |
Real-time multimodal reasoning |
3. Arsitektur Utama MML 2025
| Pendekatan |
Cara Kerja |
Contoh Model |
| Early Fusion |
Gabung data di input (concatenate) |
Audio + spectrogram → speech recognition |
| Late Fusion |
Proses terpisah → gabung di output |
ViLBERT, LXMERT |
| Cross-Attention |
Token gambar ↔ token teks |
Flamingo, BLIP-2 |
| Unified Embedding |
Semua modalitas → satu ruang vektor |
CLIP, ImageBind |
| Mixture-of-Experts (MoE) |
Router pilih expert per modalitas |
Mixtral-8x22B-Vision |
| Tokenization Universal |
Gambar → patch, audio → frame, teks → word |
Chameleon, Gemini |
4. Modalitas yang Didukung (2025)
| Modalitas |
Input Contoh |
Model Terkini |
| Teks |
Kalimat, dokumen |
Llama-3, Qwen-2 |
| Gambar |
Foto, diagram, X-ray |
CLIP, DINOv2 |
| Video |
Klip YouTube, dashcam |
Video-LLaMA, Gemini 1.5 |
| Audio |
Suara, musik, ultrasound |
Whisper, AudioCLIP |
| 3D/Point Cloud |
LiDAR, MRI |
Point-E, ShapeNet |
| Sensor |
IoT, wearable (ECG, IMU) |
SensorBERT |
| Tabular |
CSV, database |
TabTransformer + CLIP |
5. Aplikasi Multimodal 2025
1. Healthcare
- Model: Med-PaLM M
- Input: X-ray + laporan dokter + riwayat pasien
- Output: Diagnosis + rekomendasi pengobatan
- Akurasi: 92% di kasus pneumonia (vs 78% dokter junior)
2. Autonomous Driving
- Model: Tesla FSD 13.2
- Input: 8 kamera + radar + GPS + suara klakson
- Output: Prediksi lintasan pejalan kaki
- Latensi: <50 ms
3. Creative AI
- Model: DALL·E 4 + AudioCraft
- Input: “Buat lagu jazz dengan gambar kota hujan”
- Output: Video musik + soundtrack AI
4. Education
- Model: Khanmigo Vision
- Input: Foto soal fisika tulis tangan
- Output: Penjelasan langkah-demi-langkah + animasi
5. Retail & E-commerce
- Model: Amazon Rufus Vision
- Input: Foto baju + suara “cari yang mirip tapi warna biru”
- Output: Rekomendasi real-time
6. Dataset Multimodal Terbesar (2025)
| Dataset |
Ukuran |
Modalitas |
Link |
| LAION-5B |
5,8 miliar |
Image + text |
laion.ai |
| YouTube-8M |
8 juta video |
Video + audio + text |
Google Research |
| WebVid-10M |
10 juta |
Video + caption |
webvid.org |
| AudioSet |
2 juta klip |
Audio + label |
Google |
| MM1.5 Dataset |
1,5 miliar |
7 modalitas |
Meta AI |
7. Tantangan Utama MML
| Tantangan |
Solusi 2025 |
| Data Alignment |
Contrastive loss (CLIP-style) |
| Compute Cost |
MoE, quantization, sparse attention |
| Hallucination |
Grounding dengan retrieval (RAG multimodal) |
| Bias Cross-Modal |
Fairness audit per modalitas |
| Privacy |
Federated learning + differential privacy |
8. Benchmark Multimodal 2025
| Benchmark |
Tugas |
Top Model |
Skor |
| VQA v2 |
Visual QA |
GPT-4o |
87.2% |
| MMMU |
Multi-discipline |
Gemini 1.5 Pro |
78.3% |
| VideoMME |
Video understanding |
Video-LLaMA-2 |
72.1% |
| M4C |
Chart QA |
Qwen-VL-Chat |
91.4% |
| AudioBench |
Audio reasoning |
Whisper + Llama |
88.7% |
9. Tren Masa Depan (2026–2030)
- Embodied Multimodal AI Robot yang melihat + mendengar + bergerak (Figure 02, Boston Dynamics)
- Real-Time Multimodal<100 ms latency untuk AR glasses (Apple Vision Pro 2)
- 6+ Modalitas Teks + gambar + audio + video + smell (digital olfaction)
- Open-Source MMLLLaVA-Next, InternVL-2 → democratize akses
- Multimodal AGI Model yang belajar dari dunia fisik seperti bayi manusia
10. Tools & Framework untuk Membangun MML
| Tool |
Fitur |
Link |
| Hugging Face Transformers |
100+ model multimodal |
huggingface.co |
| LAVIS Library |
BLIP, ALBEF, training pipeline |
GitHub |
| PyTorch Multimodal |
Custom fusion layers |
pytorch.org |
| OpenCLIP |
Train CLIP dari nol |
GitHub |
| DeepSpeed-MII |
Inference 10x lebih cepat |
Microsoft |
Multimodal Machine Learning bukan sekadar tren—ia adalah evolusi menuju AI yang benar-benar cerdas. Seperti manusia, AI masa depan tidak hanya membaca, tapi melihat, mendengar, dan memahami konteks.